
Not God but Man Makes Pot and Pan
On the Verge of Creating a New Project
Let’s pretend the business driving our small, but free and proud tech team claims for a new feature. We are smart enough to not reinvent the wheel from scratch, so we go on a deep internet trip to discover what was successfully built under the similar requirements by our mate developers. It turns out, the existing solutions coverage is shallow, vague and contradictory.

There is a huge load of articles, with nearly 50-50 ratio, sharing both success stories and drastic failures. Some advocate for using Foo over Bar, while others ensure to pick up Baz on top of Boo and avoid Foo at any cost. We filter out the news from the sources we have never heard about and end up with some advice coming from a trustful one. Which is either a proven authority because of a dozen written books and courses, or is simply too big to fail. Like, you know, Goozone Hawk Co. could not get it wrong.
This is the authority bias as it is. Hype does spread both the correct and the very wrong ideas equally fast. I do not get why this white-bearded guy could not be wrong. I need my own opinion.
Gimme a Fulcrum and a Lever
Since several years ago I have been approaching every single problem with writing my own code. Well, almost every single problem. I am not going to rewrite the operating system, the database engine, or the container manager. But if it looks like a one-week-stand and quacks like a one-week-stand, I would enter the same river again.
What do we need to implement this time? A sophisticated monitoring system to prove we are fifteen-nines-compatible.
We are running a mission-critical system. Nah, I understand that each business considers their mission being critical, but here in Fintech it’s a bit more of a truth. I do recall one talk at a conference about highload system (from the company which indeed serves gazillions requests per a second,) when the speaker bragged about they fail to respond to less than one pro mille requests. In our case the allowed number of requests we can fail on in exactly zero.
Besides that, we deal with many third-party services what makes us vulnerable to the failures provoked by unpredictable and, in general, unknown sources. The single “transaction” might last hours since it requires approval by many external authorities before real execution. We are kinda experts in talking a bitty language; all these negotiations are done purely machinery-to-machinery.
That list might be continued for three screens more, including, but not limited to:
- potential need of manual intervention
- high concurrency of many different processes
- lots of highload queues to listen to to get the actual data for different matters
- ability to roll back anything
- necessity to audit every single step both internally and in another 3rd-party service
- orchestrating all that zoo to make sure we have it paid before shipped
We obviously have the scraps of monitoring inplace, and I bet most internet businesses in other areas would consider our monitoring bullet-proof, but we cannot blindly trust in Unicorns and Pink Fairies keeping us safe.
OK. We need a fulcrum and a query so we could ask internets what path should we follow to move the Earth toward the right direction. Unfortunately it was easier said than done. And here I indulged my sin. I dove to…
Inventing the Wheel
What Do We Have
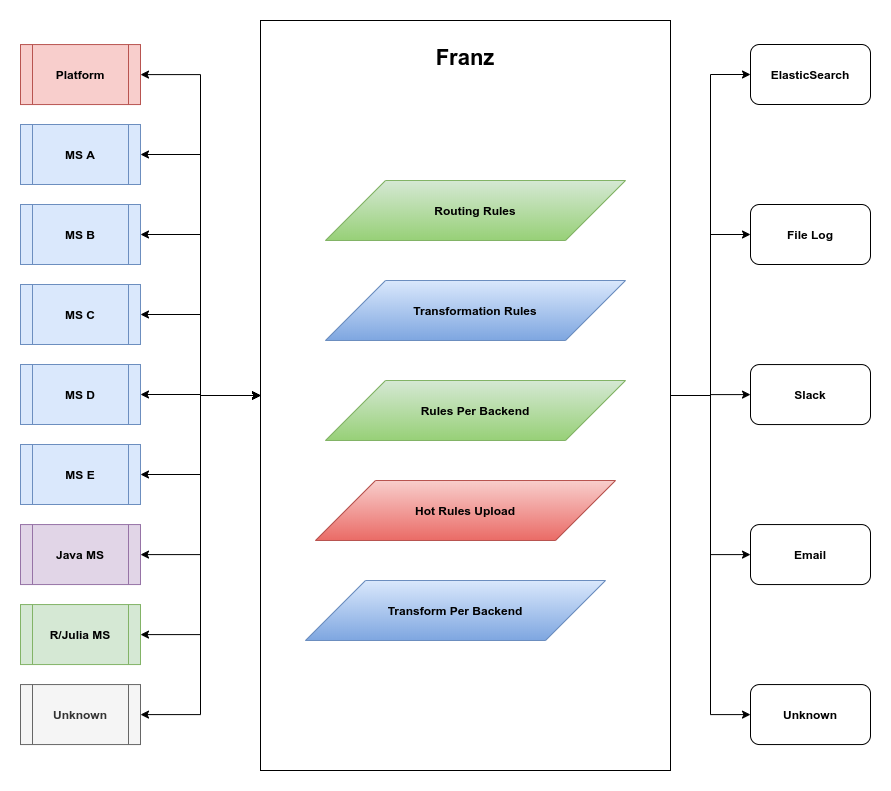
All services on the left side run in the cloud, some have several instances in parallel, some have several instances in a cluster, some are singletons. The whole idea was born as let’s have a better visibility and has evolved into we might build the Event Log that would serve the purpose of tracking all the changes and providing rollback abilities in case of failures.
So, how would we approach this?
Pair Monitoring
Do you remember how have you been excited exercising the pair programming technique for the first time? It was an amazing feeling, was not it? That reminiscence granted me an idea to do pair monitoring. Not only the containers infrastructure health-checks applications management and the applications infrastructure health-checks the business logic, but the play as a team, reporting issues back and forth.
Say ‘No’ to Transactions
There should be no transactions. Only atomic operations are supported. Rolling back a transaction on the application level would be an ad-hoc, informally-specified, bug-ridden, slow implementation of half of the database engine and we agreed to avoid reimplementing monsters.
Keep Track of Literally Everything
Despite the existence of long-lived ‘transactional’ actions in our environment, we found that we might split everything into atomic actions driven by finite-state automata. Instead of having a transaction, involving changes of several different objects, we introduce another object, which plays the role of the transaction fsm. During the lifecycle of this object, all the underlying objects are marked as in transaction. Once it gets to commit, all the changes are applied simultaneously, generating several lines in the event log, one per an atomic action. That way we always have an ability to rollback anything afterwards.
Also, there are some actions that cannot be rolled back (e. g. the actual money transfer.) We clearly mark them in the event log and for each of such actions we introduce the ‘rollback’ object, that does the action that is mimicking the real life rollback (e. g. transfer the same amount backward for the contrived example above.)
Dry Run
Each and every internal transaction should be availbale in dry-run mode. With all the external calls mocked and all the logs and notifications enabled. That way it’d be possible to apply Chaos Testing in production, while testing new features or debugging known issues with existing ones.
Orchestration vs Choreography
These two approaches are usually mentioned as mutually exclusive. We discovered it is not the case at all. One might encapsulate parts of the whole system according to SRP into orchestrated beasts, who play well in the event-driven choreography and vice versa.
We also need to be able to put boundaries on the imaginary diagram representing our architecture at a glance. It would look mostly like a political map of the world. Boundaries cannot cross over. The states within boundaries are responsible for rules inside the state. They literally have their own goverments, laws, whatever. Communication inside the single boundary might be done as the state laws dictate; the communication between different states is done via diplomatic mail; that said, with message passing.
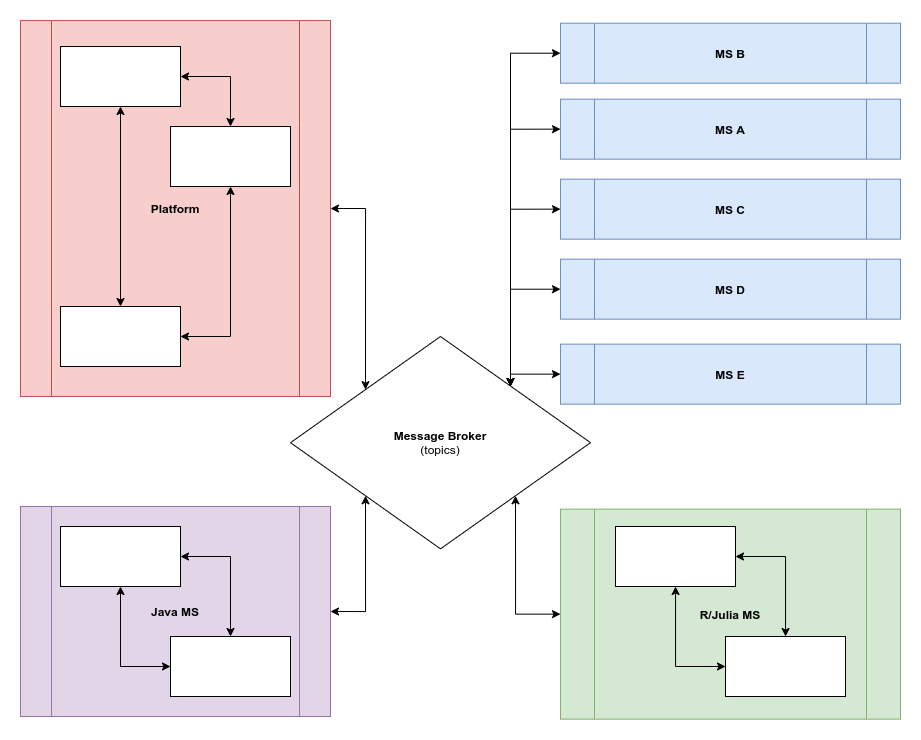
All the messages have topics; whatever state is interested in the topic should explicitly subscribe to it. Whether there are several instances of the same service running in the cluster, they should decide how to handle and share the arriving messages amongst nodes (the easiest and most robust implementation would be the hashring-based one.)
Ack, Please
All the messages are to be acked upon processing. The receiver of the acknowledgement is not necessarily the service who sent the original message. Acks might be chained. The event log (who is subscribed to everything) keeps track of all the acks and alerts in the case there are some unacked messages.
Play / Rewind
Event logs might be used to reproduce failing (suspicious) scenarios in staging later. This part is kinda complicated and we are not going to implement it right now, but the whole architecture is built with this ability in mind.
Chaos Testing
The whole system is to be tested by sending unexpected and corrupted messages, by plugging and unplugging service instances, by mimicking network splits and remote services failures.
The above is the list of requirements, that is to be constantly expanded.
Standing on the Shoulders of Giants
I have to say, that in a vast majority of cases, wheels invented by me during the problem analyzing stage were born squared, spokeless and fragile. I was throwing them directly into the trashcan with an easy heart to pick up one of mature, proven by community battles, solutions. But not at that time.
We have examined similar attempts done by Netflix (Orchestrator, Data Capture,) Sharp End (AWS + Chaos Monkey,) OpenPolicyAgent, many built-in cloud provider’s infrastructure tools, but the song remained the same.

It sounded like we do need our own, invented here, solution.
Conclusion
The bigger the company, the more failures they experience on each step. Do not blindly follow advices and good practices published by authorities. Use the time dedicated to problem analysis wisely. Learn on your own mistakes before picking up one of the proper solutions presented on the market. Or, rarely but surprisingly satisfactory, see for yourself, that your wheel trundles smoothly and is indeed better than whatever was created by humanity before. It’d be a great time to enjoy being a smart developer.
Happy wheelinventing!